
人工知能(AI)を研究する非営利団体のOpenAIが、自然言語処理と画像生成を組み合わせたAI「DALL・E」を発表しました。DALL・Eは人間と見分けが付かないほど高精度な文章を生成するAI「GPT-3」のパラメータを使用し、文章からイラストや写真を作り出すことができます。
DALL·E: Creating Images from Text
https://openai.com/blog/dall-e/
OpenAI debuts DALL-E for generating images from text | VentureBeat
https://venturebeat.com/2021/01/05/openai-debuts-dall-e-for-generating-images-from-text/
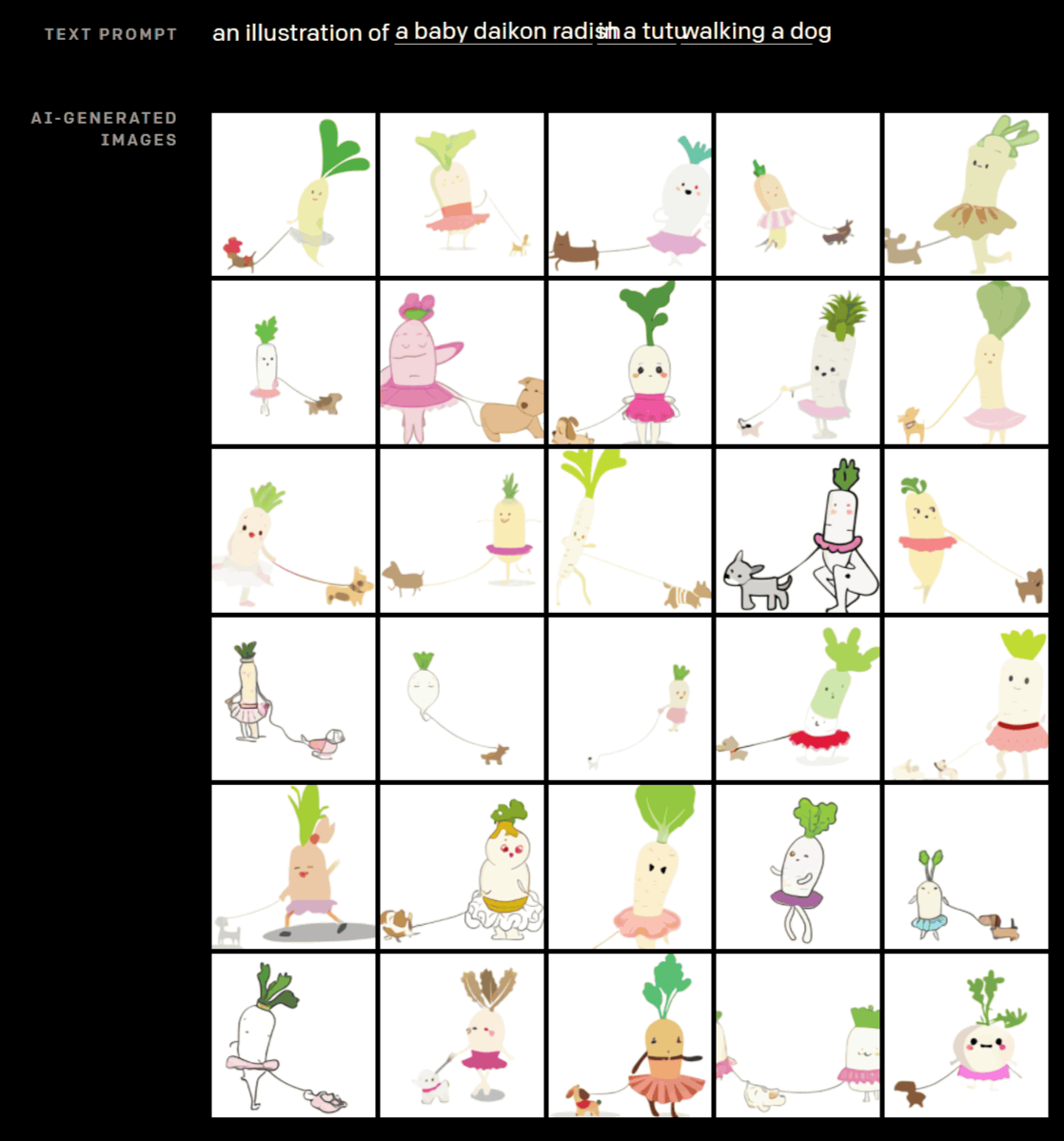
OpenAIの公式ブログでは、実際に「DALL・Eに入力したテキスト」と「DALL・Eが出力した画像」を公開しています。例えば「『チュチュを着て』『犬の散歩をする』『大根』」のイラストはこんな感じ。DALL・Eは、「チュチュを着て」と「犬の散歩をする」と「大根」というような、互いに無関係な複数のテキスト要素から、この世に存在しない画像を自動で作り出すことができるのが特徴です。
「『パジャマを着て』『バイクに乗る』『ピカチュウ』」と入力すると、以下のようなイラストが生成されます。

また、出力する画像はイラストだけではなく写真も可能。例えば「『アボカド』の『ような形をした』『椅子』」というテキストを入力すると、以下のような画像が出力されます。出力された画像はまるで写真のようですが、DALL・Eが生成したもので、このような椅子は存在しません。

「『OpenAI』という『看板を掲げた』『店頭写真』」と入力するとこんな感じ。もちろん「OpenAI」という看板は現実には存在せず、すべてAIが文章をレンダリングし、ネオンサインや看板を作り上げています。画像を見ると、一部には「OpenII」「OPEAAI」など、生成に失敗しているものもありました。OpenAIによれば、求められる文字列が長いほど画像生成の成功率は低くなるそうです。

ほかにも、DALL・Eは地理的知識や時間的知識にも対応しているとのこと。例えば、「サンフランシスコの『ゴールデン・ゲート・ブリッジ』の写真」というテキストと、背景をイメージする画像を一緒に入力すると、以下のようにゴールデン・ゲート・ブリッジの画像を自動で生成します。

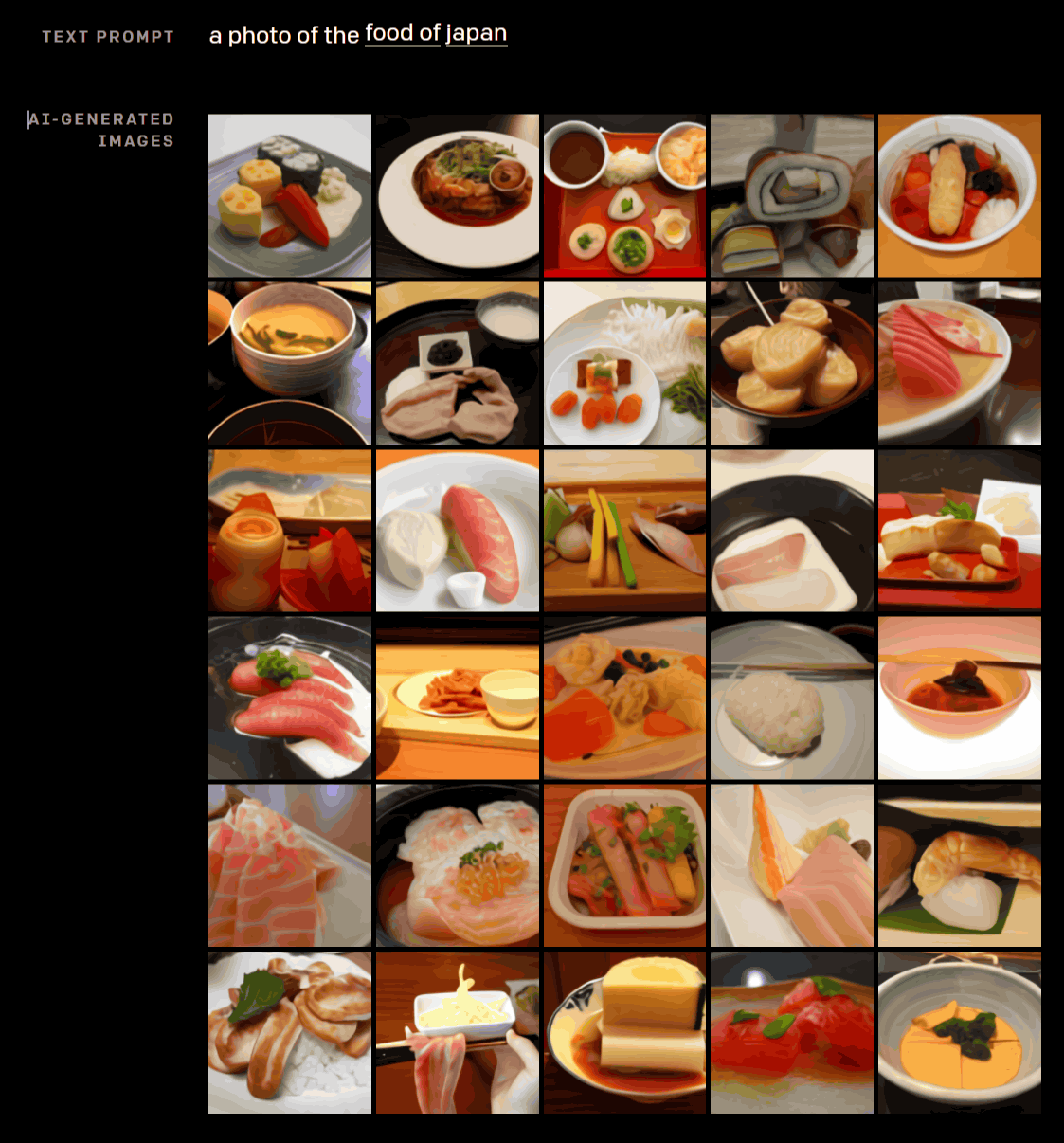
また、「『日本』の『食べ物』」と入力すると、出力された写真が以下。寿司、刺身や煮物など、和食らしい写真が並んでいますが、盛り付けはかなりいい加減にも見えます。
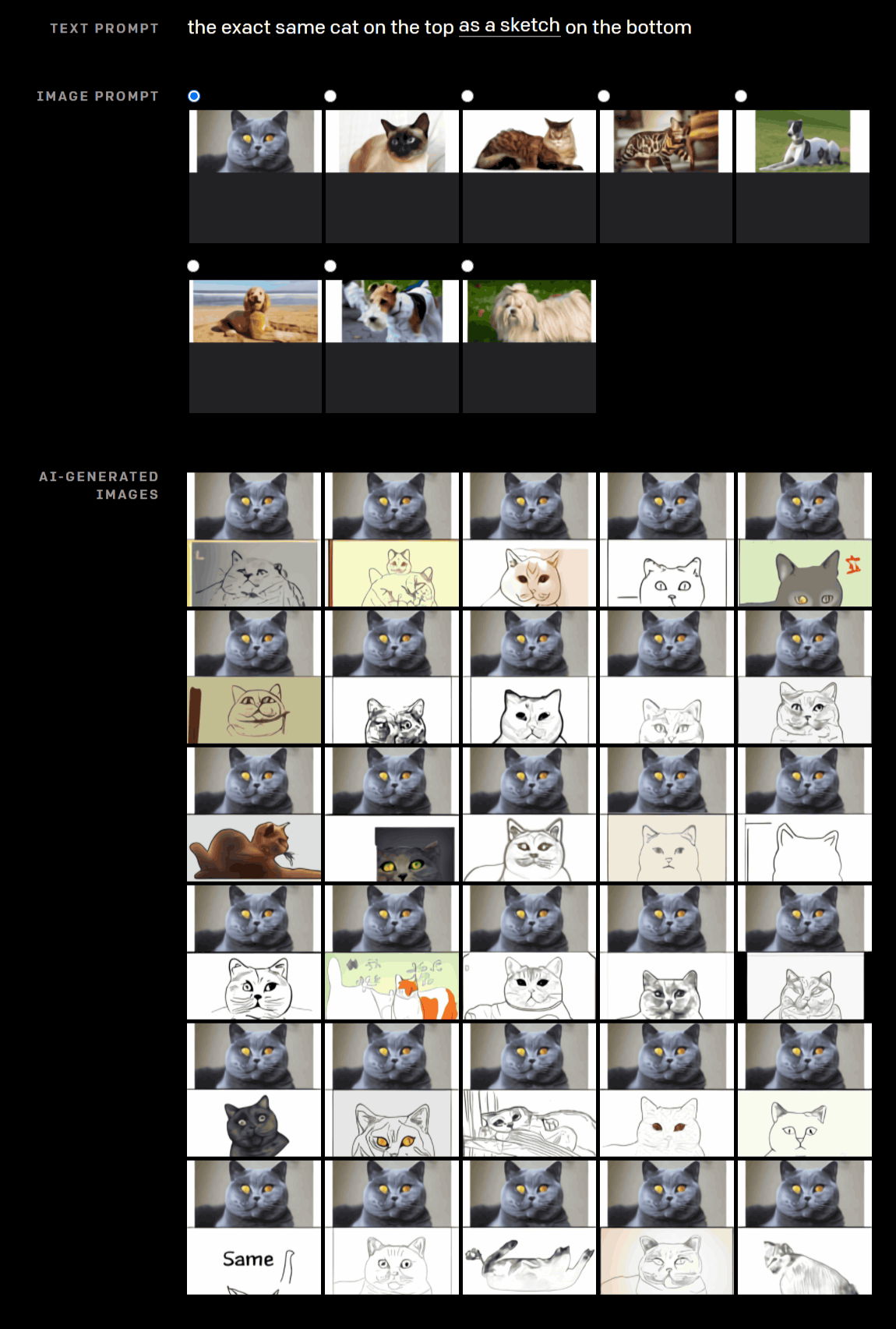
さらに、猫の写真と共に「入力した画像に写っている『猫』のスケッチの画像を、元画像の下に表示する」という文章を入力すると、以下のようにスケッチを自動生成します。スケッチを見てみると、かなりそっくりに描かれたものから、まったく違う猫を描いているもの、「same(同じ)」と描いて諦めてしまったものなど、多種多様なスケッチが出力されています。
OpenAIは「私たちは、生成モデルを含むDALL・Eの処理結果が、社会に重大かつ広範な影響を与える可能性があると認識しています。今後は、DALL・Eのようなモデルが、特定の業務プロセスや専門職への経済的影響、モデルのアウトプットにおけるバイアスの可能性、この技術が示唆する長期的な倫理的課題などの社会的課題とどのように関連しているかを分析する予定です」とコメントしています。
なお、「DALL・E」という名前は、画家のサルバドール・ダリと、ロボットが主人公の長編アニメーション映画「WALL・E」にちなんでいるとのことです。
この記事のタイトルとURLをコピーする
からの記事と詳細 ( 「バイクに乗るピカチュウ」「アボカドの椅子」など言葉から自動でイラストや写真を生成するAI「DALL・E」 - GIGAZINE )
https://ift.tt/35ffg4t
No comments:
Post a Comment